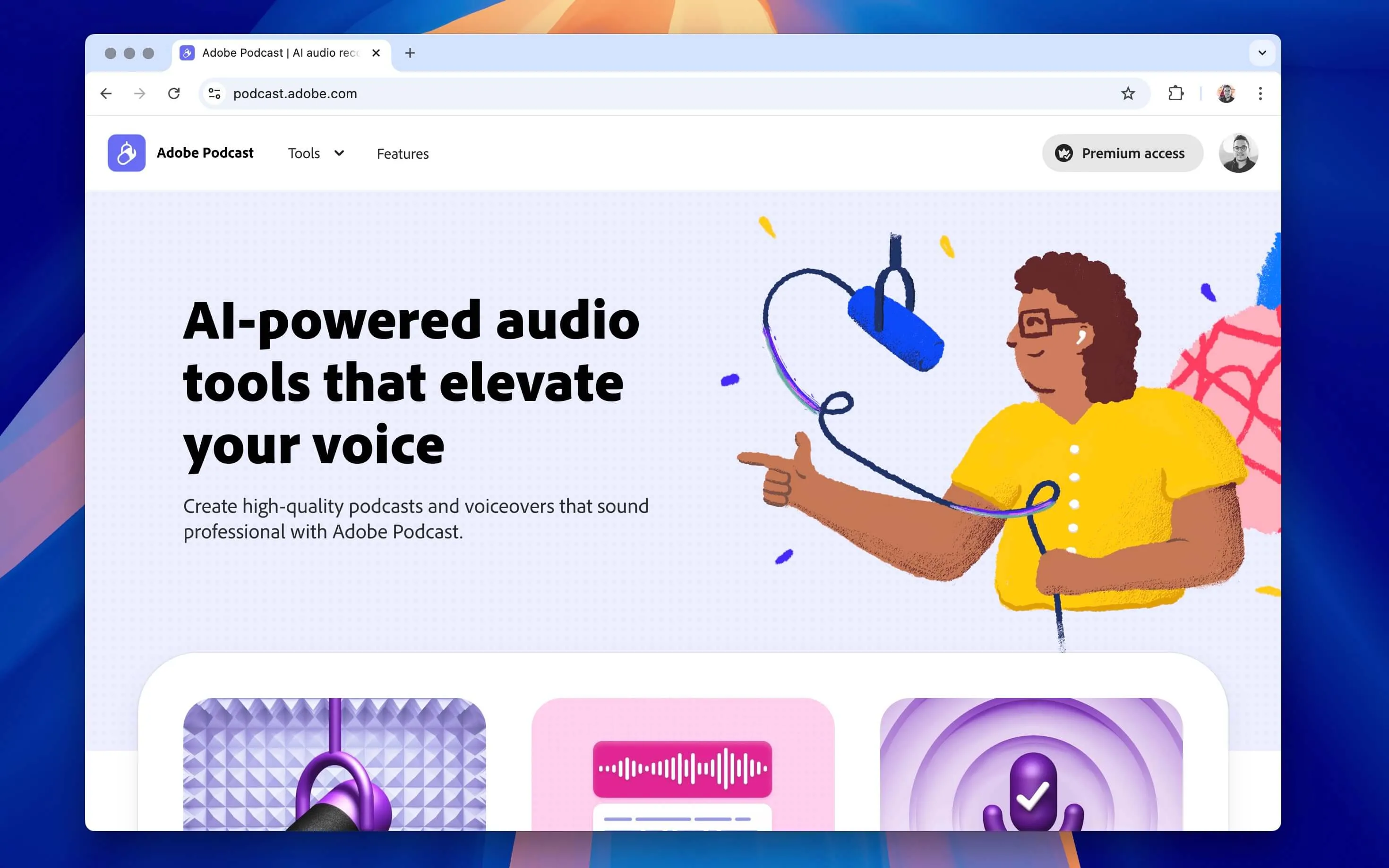
Adobe Podcast.
Adobe Podcast Product
I lead product for Adobe Podcast—developing AI tools that enhance spoken audio. I work closely with research and engineering to turn audio models into tools like Enhance Speech—improving clarity by reducing noise—and Studio, which enables multi-language speech-to-text, making it easier to edit speech like a document.
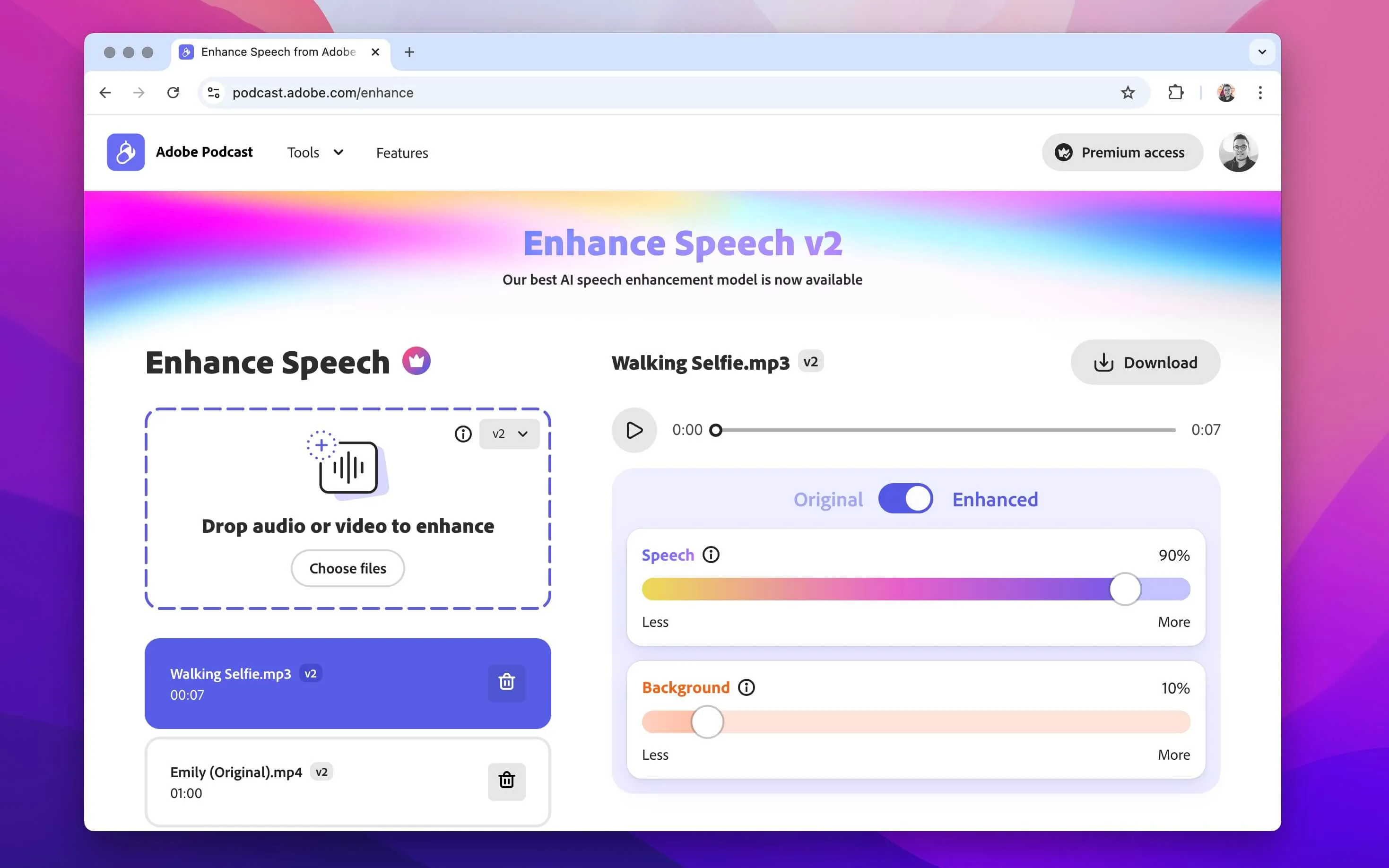
Enhance Speech Product Feature
I partnered with Adobe research, design, and engineering to productize generative audio models for stem separation and speech enhancement. Enhance Speech helps users clean up recordings for interviews, podcasts, and more—refining dialogue, reducing noise, and delivering studio-quality audio without professional equipment or post-production tools.
Speech to Text Product Feature
By leveraging generative audio models, I helped build multi-language speech-to-text transcription in Studio, allowing users to seamlessly record and transcribe audio. Users can edit transcripts like a document, making it easier than ever to edit audio without complex tools or manual waveform editing.
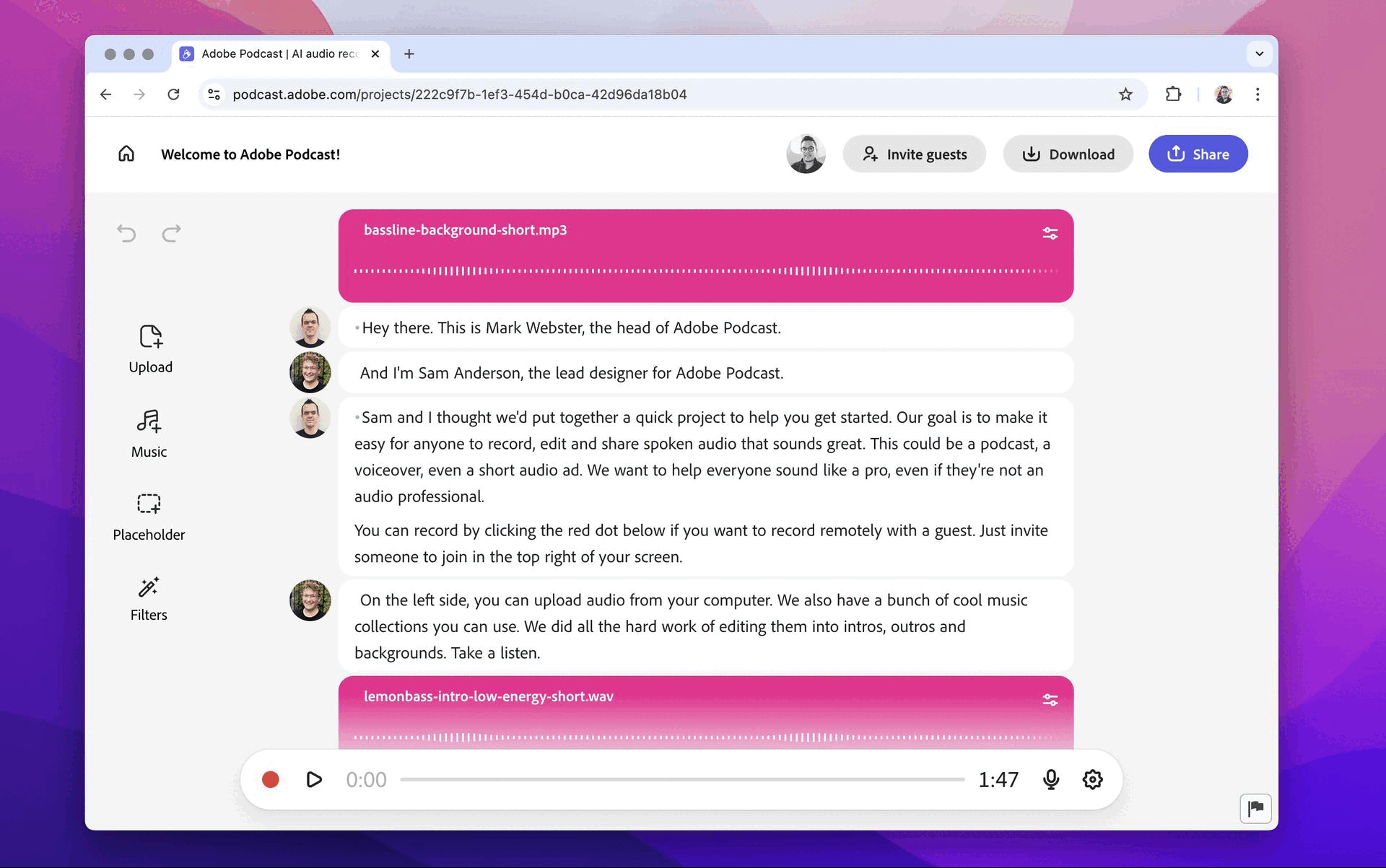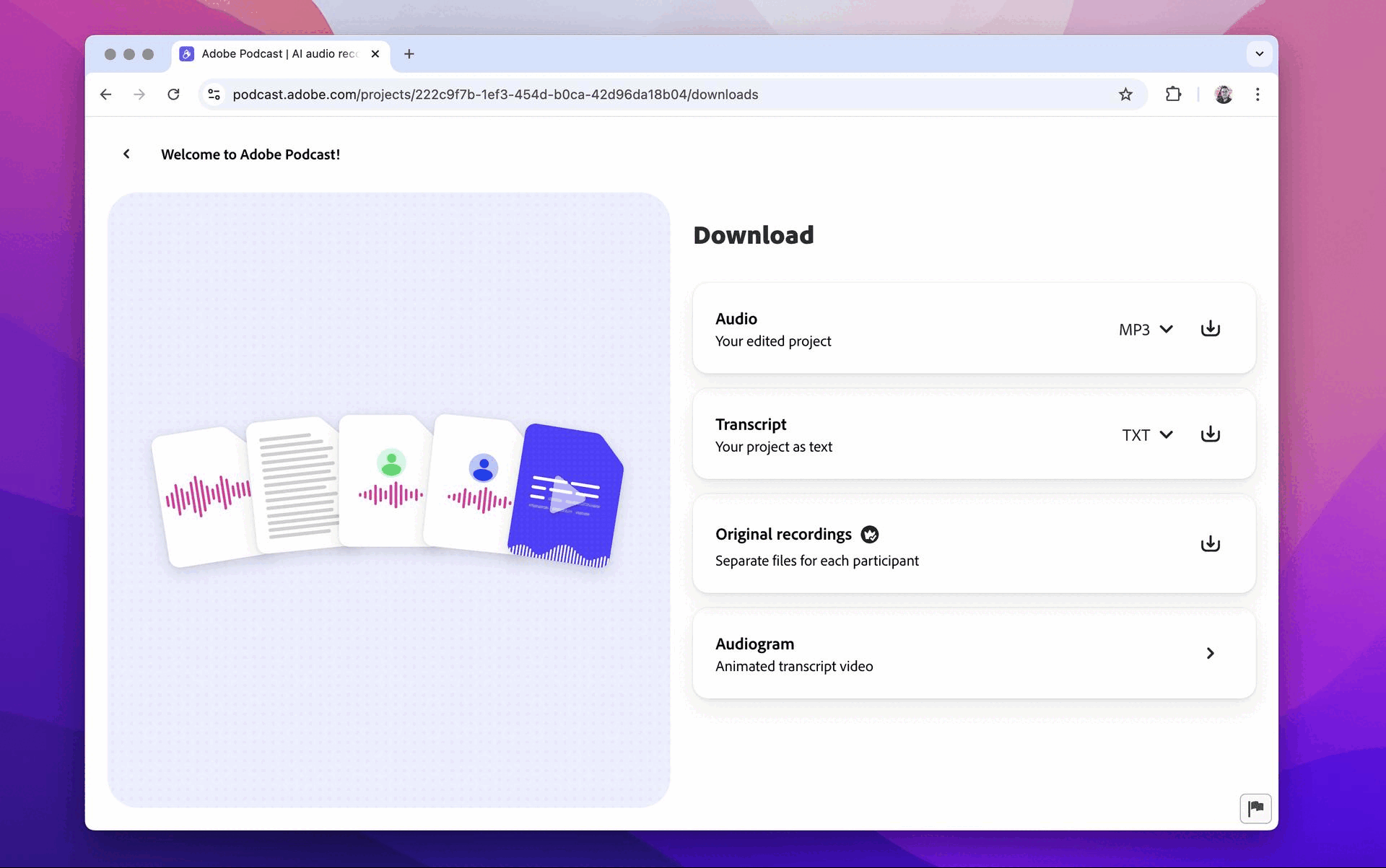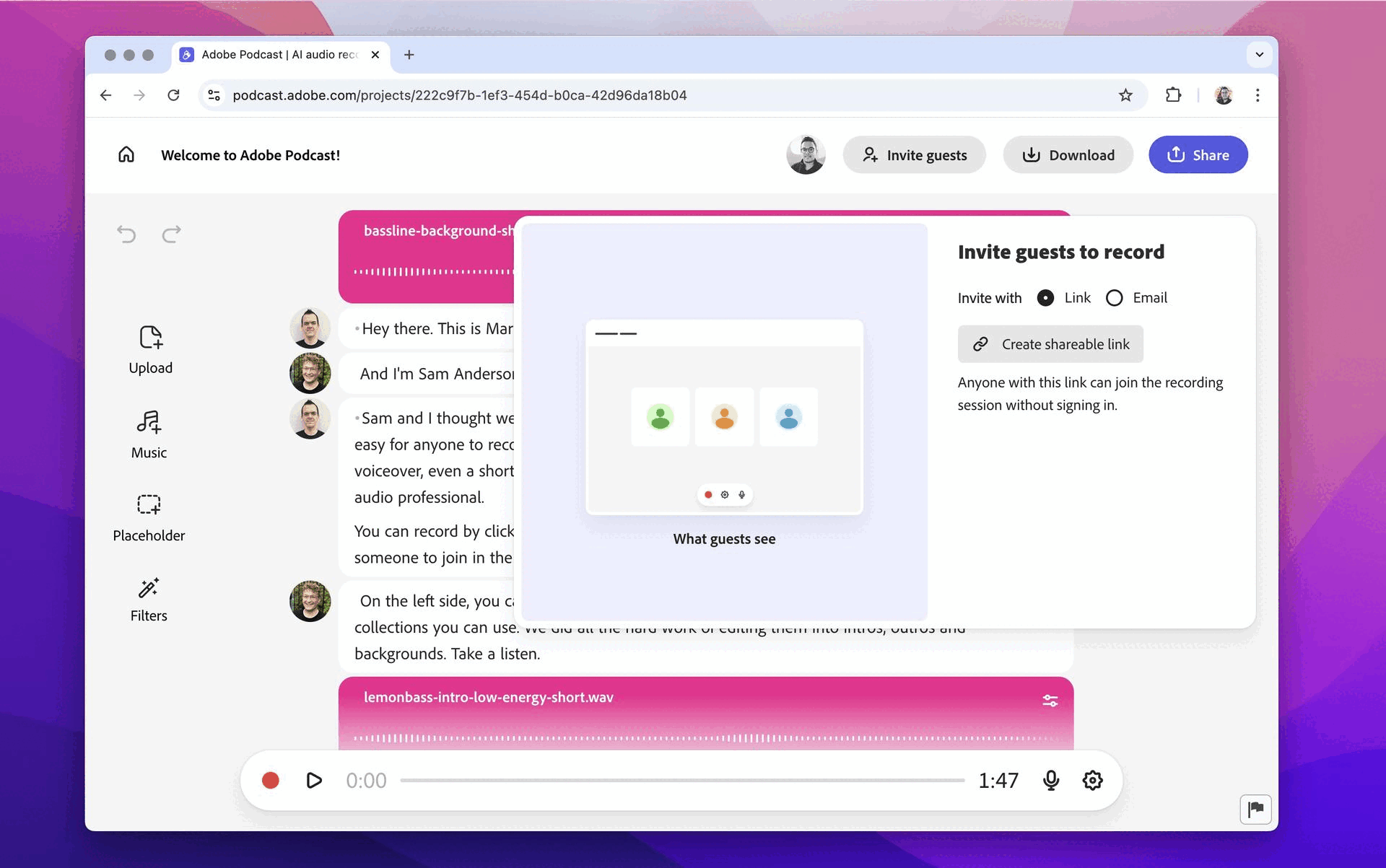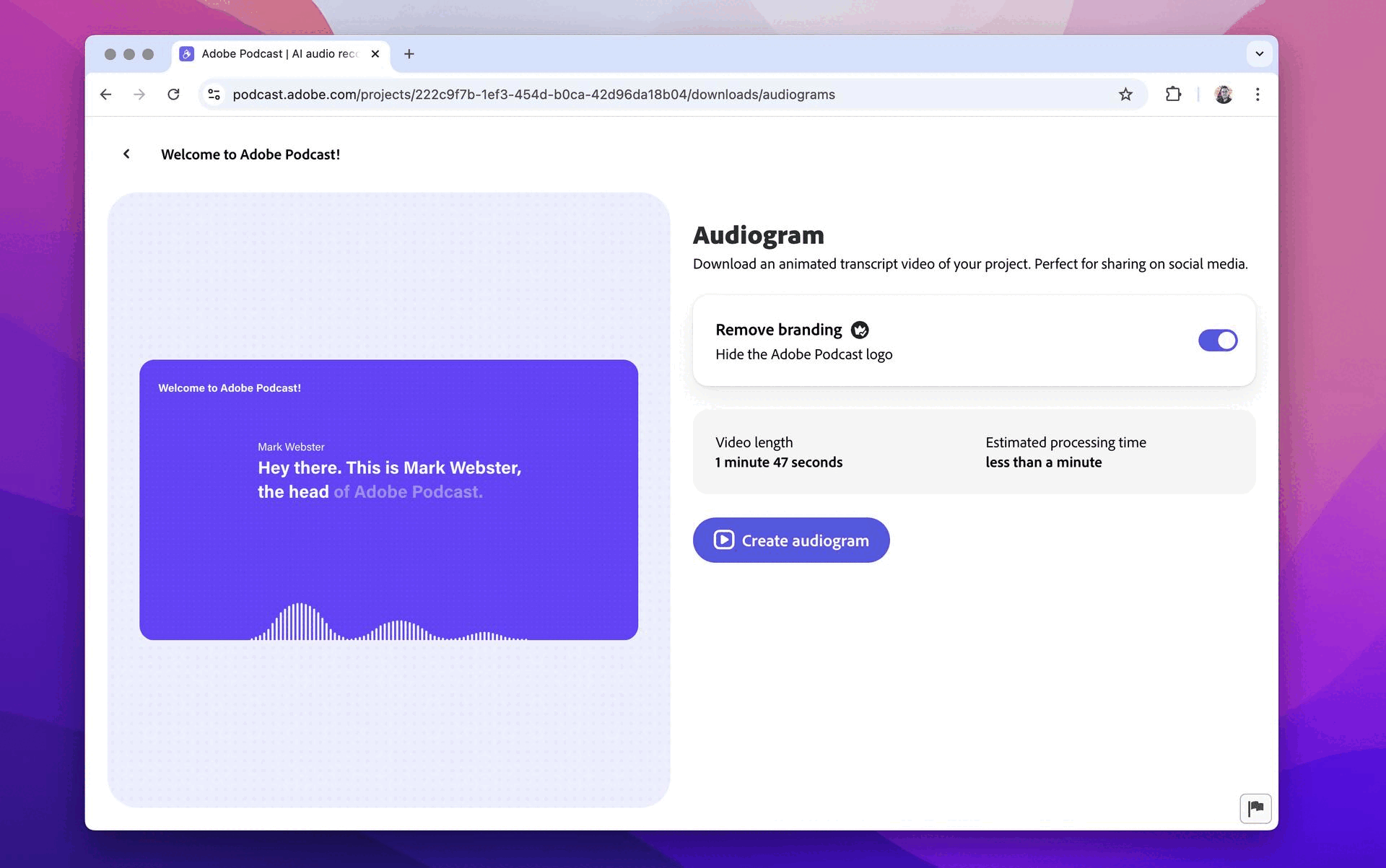
Home Studio
Travel Influencer
Try the audio mixing tool Claude
Generate an audio file that switches between the original and enhanced versions every five seconds, making it easy to compare quality differences at a glance.
Try the stem mixing tool Claude
Upload and remix individual audio stems in real-time to preview how speech, background, and reverb blend together before finalizing the mix. Save each mix as a preset for easy resue.
Adobe Podcast
podcast.adobe.com
AI-powered audio tools that elevate your voice. Create high-quality podcasts and voiceovers that sound professional with Adobe Podcast.
Podcast →